概率图模型
概率图模型(probabilistic graphical models)在概率模型的基础上,使用了基于图的方法来表示概率分布(或者概率密度、密度函数),是一种通用化的不确定性知识表示和处理方法。在概率图模型的表达中,结点表示变量,结点之间直接相连的边表示相应变量之间的概率关系。当概率分布P被表示成概率图模型之后,可以用来回答与概率分布P有关的问题,如计算条件概率P(Y|E=e):在证据e给定的条件下,Y出现的边缘概率;推断使P(X1,X2,L,Xn|e)最大的(X1,X2,L,Xn)的分布,即推断最大后验概率时的分布argmaxXP(X|e)。例如,假设S为一个汉语句子,X是句子S切分出来的词序列,那么,汉语句子的分词过程可以看成是推断使P(X|S)最大的词序列X的分布。而在词性标注中,可以看作在给定序列X的情况下,寻找一组最可能的词性标签分布T,使得后验概率P(T|X)最大。
根据图模型(graphical models)的边是否有向,概率图模型通常被划分成有向概率图模型和无向概率图模型。我们可以粗略地将图模型表示成图6-1所示的树形结构。

动态贝叶斯网络(dynamic Bayesian networks, DBN)用于处理随时间变化的动态系统中的推断和预测问题。其中,隐马尔可夫模型(hidden Markov model, HMM)在语音识别、汉语自动分词与词性标注和统计机器翻译等若干语音语言处理任务中得到了广泛应用;卡尔曼滤波器则在信号处理领域有广泛的用途。马尔可夫网络(Markov network)又称马尔可夫随机场(Markov random field, MRF)。马尔可夫网络下的条件随机场(conditional random field, CRF)广泛应用于自然语言处理中的序列标注、特征选择、机器翻译等任务,波尔兹曼机(Boltzmann machine)近年来被用于依存句法分析和语义角色标注等。
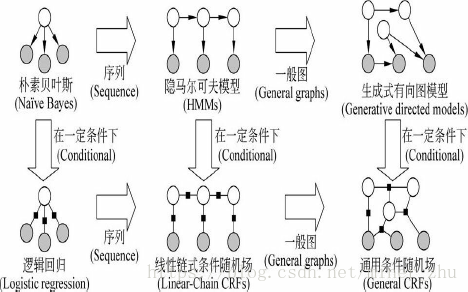
图6-2从纵横两个维度更加清晰地诠释了自然语言处理中概率图模型的演变过程。横向:由点到线(序列结构)、到面(图结构)。以朴素贝叶斯模型为基础的隐马尔可夫模型用于处理线性序列问题,有向图模型用于解决一般图问题;以逻辑回归模型(即自然语言处理中ME模型)为基础的线性链式条件随机场用于解决“线式”序列问题,通用条件随机场用于解决一般图问题。纵向:在一定条件下生成式模型(generative model)转变为判别式模型(discriminative model),朴素贝叶斯模型演变为逻辑回归模型,隐马尔可夫模型演变为线性链式条件随机场,生成式有向图模型演变为通用条件随机场。
生成式模型(或称产生式模型)与区分式模型(或称判别式模型)的本质区别在于模型中观测序列x和状态序列y之间的决定关系,前者假设y决定x,后者假设x决定y。
生成模型以“状态(输出)序列y按照一定的规律生成观测(输入)序列x”为假设,针对联合分布p(x, y)进行建模,并且通过估计使生成概率最大的生成序列来获取y。生成式模型是所有变量的全概率模型,因此可以模拟(“生成”)所有变量的值。在这类模型中一般都有严格的独立性假设,特征是事先给定的,并且特征之间的关系直接体现在公式中。这类模型的优点是:处理单类问题时比较灵活,模型变量之间的关系比较清楚,模型可以通过增量学习获得,可用于数据不完整的情况。其弱点在于模型的推导和学习比较复杂。典型的生成式模型有:n元语法模型、HMM、朴素的贝叶斯分类器、概率上下文无关文法等。
判别式模型则符合传统的模式分类思想,认为y由x决定,直接对后验概率p(y|x)进行建模,它从x中提取特征,学习模型参数,使得条件概率符合一定形式的最优。在这类模型中特征可以任意给定,一般特征是通过函数表示的。这种模型的优点是:处理多类问题或分辨某一类与其他类之间的差异时比较灵活,模型简单,容易建立和学习。其弱点在于模型的描述能力有限,变量之间的关系不清楚,而且大多数区分式模型是有监督的学习方法,不能扩展成无监督的学习方法。代表性的区分式模型有:最大熵模型、条件随机场、支持向量机、最大熵马尔可夫模型(maximum-entropy Markov model, MEMM)、感知机(perceptron)等。
下面将简要介绍贝叶斯网络和马尔可夫网络的基本概念。由于自然语言处理中需要解决的问题大多数属于“线”的序列结构,因此我们分别以HMM(生成式)和线性链式CRF(判别式)为例来介绍自然语言处理中的概率图模型。其中,HMM以朴素贝叶斯(naΪve Bayes)为基础, CRF以逻辑回归为基础。
隐马尔可夫模型:NLP之隐马尔可夫模型